背景
以前更多精力关注在付费流量,比如Facebook、Google的付费采买,直到后来看到了 硅谷增长黑客 一书 讲到 付费流量当打通工程链路后,余下的无非就是 花钱买流量了。
他们反而喜欢做免费流量,因为免费流量不用花钱,创业公司更喜欢。
所以这边也开始整理SEO相关的知识。
canonical 标签有什么用呢?
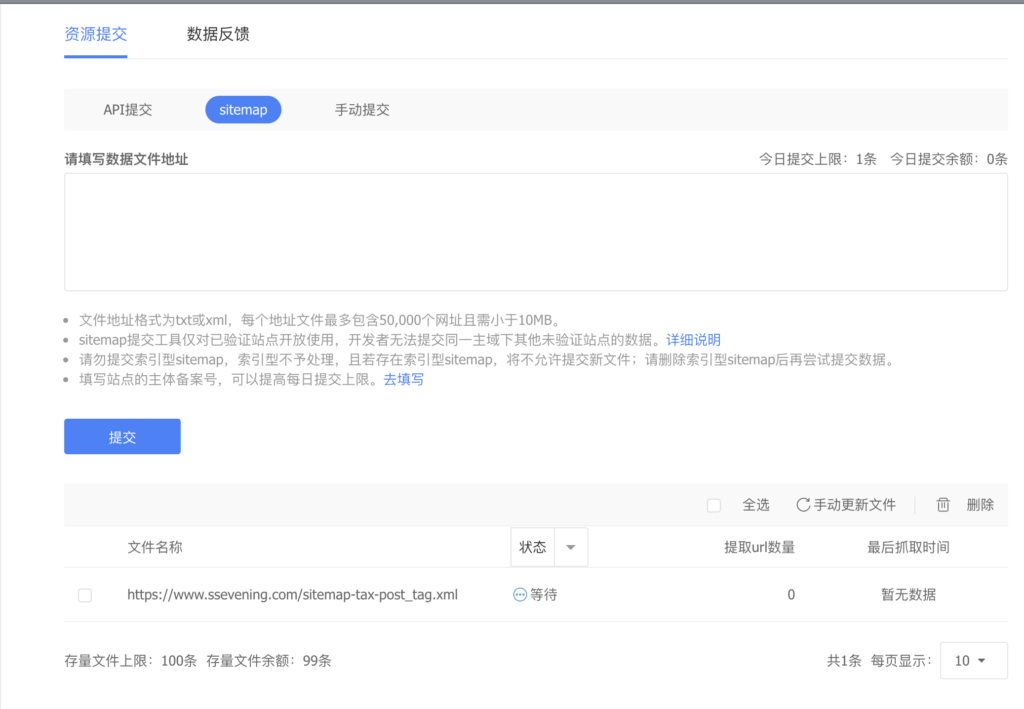
通常情况下,为了统计页面的PV打点和来源之类的,我们站内的URL 经常会添加很多参数,比如:spm参数,或者src参数。
比如 aliexpress 的产品详情页:
https://www.aliexpress.com/item/1005002510050980.html?spm=a2g0o.home.15002.1.650c2145XTWfnp&gps-id=pcJustForYou&scm=1007.13562.225783.0&scm_id=1007.13562.225783.0&scm-url=1007.13562.225783.0&pvid=7805e548-3bd1-4c5b-8c5b-1ed994c5134b&_t=gps-id:pcJustForYou,scm-url:1007.13562.225783.0,pvid:7805e548-3bd1-4c5b-8c5b-1ed994c5134b,tpp_buckets:668%232846%238112%231997&&pdp_ext_f=%7B%22sceneId%22:%223562%22,%22sku_id%22:%2212000021975982496%22%7D我们可以看到 在网址后面有很多参数,其中 spm 代表着用户是从哪个站点的首页的第几个坑位点击进来的,其他的参数 还会 涉及页面ID,算法分桶相关参数,用于统计用户后续的转化。
也就是说,上述的页面,如果被SEO爬取的话,每一个页面URL都不一样,就会导致SEO分散资源去爬取。
那怎么告诉SEO,网页的源网页,然后让SEO自动避坑呢?
那就用:canonical
查看上述网页的源码可以看到:
<link rel="canonical" href="https://www.aliexpress.com/item/1005002510050980.html">
这样就告诉了爬虫,这个网址最终的源网址是哪一个。
爬虫识别到此标签后面就不会迷路了。
个人微信:ssevening